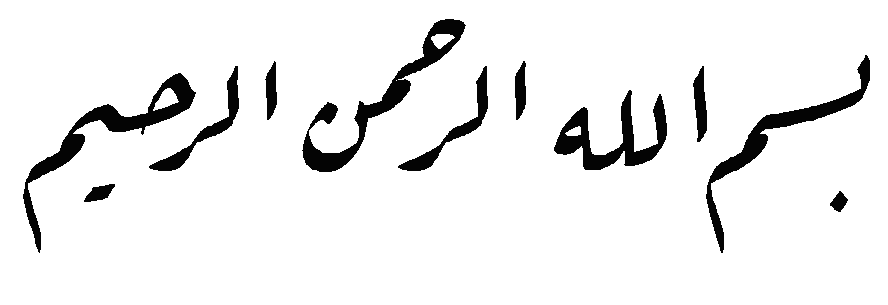[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index]
Re: Quranic Proposal
- To: "General Arabization Discussion" <general at arabeyes dot org>
- Subject: Re: Quranic Proposal
- From: "Thomas Milo" <t dot milo at chello dot nl>
- Date: Sun, 13 Jun 2004 16:23:08 +0200
Dear Abdulhaq,
> On Sunday 13 June 2004 13:27, Thomas Milo wrote:
> > The use of repeated damma/fatha/kasra is just an example of how it could
> > be done. For modern font technology internal glyph substition is a
trivial
> > matter. Internally two Unicodes can be made a single glyph (=ligature)
or
> > one Unicode can make many glyphs (for instance multiple pen strokes to
> > build one letter).
>
> Please bear with me and follow it through on the technological/rendering
> side. What current font _standard_ never mind implementation will take two
> dammas and accent the base glyph by offsetting the second identical accent
> automatically from the first?
OpenType and DecoType (which provided the proof of concept for OT to
Microsoft) as well as Apple ATSUI (Apple Type Services for Unicode Imaging)
provide the environment where such requirements can be implemented.
> I am not a font expert so please be patient with me, but do the current
> definitions of glyph substitution allow for two identical subsequent
accents
> to be overlaid on the base glyph in a offset way?
Yes.
> How can Mac OS X be expected to take a font of whatever modern standard
and
> to know that the second glyph in a damma/damma sequence is not simply
> overlaid the first, but offset, and how will it know how much to offset
it?
If it is an OpenType font, MacOSX will use internal glyph substitution table
provided by the font. You know of course, that unicode in general and Arabic
support in particular is still being added to MacOSX as we speak.
> I know that there are multiple marks available on a base glyph but I'm not
> familiar with the intricate details of how the various accent glyphs are
> located onto the correct mark.
>
> A method I can think of off the top of my head is that a new code such as
> 'damma offset' or 'ikhfaa' is introduced which could be added as a second
> accent character in the text stream. I think you can guess that I don't
like
> it much :-)
In fact, the concept of an ikhfaa' code following regular tanween would be
the cleanset way to encode plain text. Whether tanween as such is encoded by
a single or a double code is irrelevant - I believe the Unicode standard and
the supporting fon technology is capable of handling both. BTW, there is a
third layer where substitutions can be executed: the keyboard. For instance,
lam-alif already exists as a single keystroke that equates two codes. This
circumsytance offers interesting possibiliyies for the eventual
implementation.
> >This is in fact exactly how I analyse Arabic script and why I consider
the
> >existing legacy code industrial trash. However, in our present discussion
we
> >are looking for ways to make the best of the existing Arabic block in
> >Unicode.
>
> I agree that this is how script is best rendered, but I am very surprised
if
> you mean that text should be coded like this. Do you really mean that?
As far as the rendering is concerned, this the basic principle of our ACE.
However, what I meant to say is: this is how arabic script works, therefore,
this is how it should be encoded.
> I understand your point of view that the tajweed adjustments can be viewed
as
> modulating the foregoing characters. But from a pragmatic point of view we
> have to be sure that all commonly used current rendering systems can
> actually do the job, and I have concerns even about the big players.
Pragmatically speaking, everything you want is there already. It's not
elegant, but it works, or it is supposed to work. After all, the industry
agreed to implement Unicode.
> As I think about the issue more I am considering indo-pak masaahif. These
> differentiate between long and short madd by the weight of the glyph. The
> subsequent question would be, how do we account for all the other
variations
> of glyphs that may occur in masaahif around the world?
The ones I investigated use traditional Arabic spelling conventions. For all
clarity, do you mean madd as in calligraphic madd (tatweel, keshideh) or as
in tashdeed or consonant reduplication?
> This issue comes down, as I think Muhammad rightly points out, to the
> different aims, all of which we agree with in principle but for which we
> have different priorities.
True.
> We would like to be able to easily reproduce the current almost de-facto
> standard of rendering the qur'aan.
Can be done easily with the existing code set. The most pressing issue to
get the rendering of the sequence fatha-superscript_alif correct.
> You have your noble long term goals of allowing unicode to encode the full
> richness of arabic text, past, future and present.
>From your position, at the beginning of such a project - maca kulli
li-Htiraami - it would be lang term. I have done al the work already and am
already using it.
> Can they be reconciled?
Of course. Many of my ideas have ended up as industrial concepts or even de
facto standards. Including the deplorable idea of automatically assuming
that lam-lam-alif is the ligature for Allah (theograph). I originally
researched and tested it on the basis of the grammatical constraints of the
Arabic language alone and implemented it for unvowelled Ruq'ah (see
appendix)
Regards,
t
Appendix:
The Unicodes of the phrase بسم الله الرحمن الرحيم rendered by DecoType
Ruq'ah: note that Allah has no shadda and no superscript alif because they
are not in the text source.